DCGAN for Archaeologists
2018-07-29
Learning about GANs
Melvin Wevers has been using neural networks to understand visual patterns in the evolution of newspaper advertisements in Holland. He and his team developed a tool for visually searching the newspaper corpus. Melvin presented some of his research at #dh2018; he shared his poster and slides so I was able to have a look. Afterwards, I reached out to Melvin and we had a long conversation about using computer vision in historical research.
His poster is called ‘ImageTexts: Studying Images and Texts in Conjunction’ which clearly is relevant to our work in the BoneTrade. In his research, he looks at the text for ‘bursty’ changes in the composition of the text. That is, points where the content changes ‘state’ in terms of the frequency of the word distribution. The other approach is to use Generative Adversarial Networks on the images.
So what are GAN? This post is a nice introduction and uses this image to capture the idea:
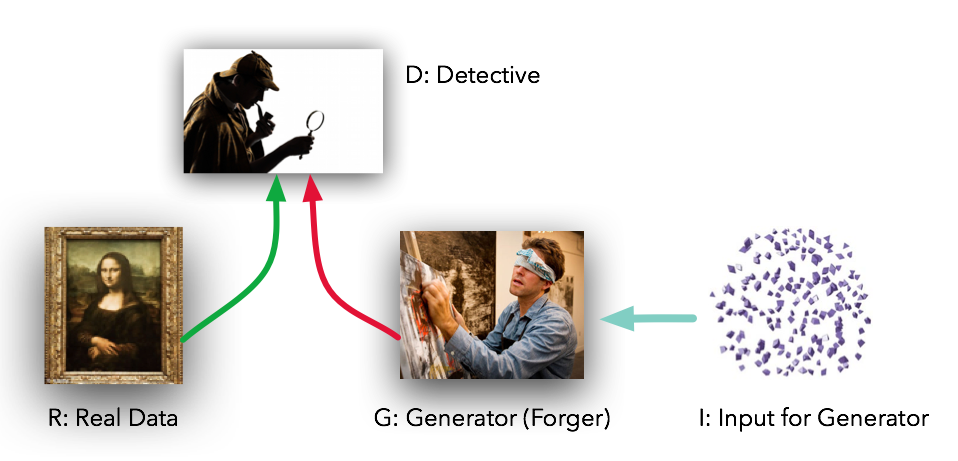
In essence, you have two networks. One learning how to identify your source images, and the second learning how to fool the first by creating new images from scratch.
Why should we care about this sort of thing? For our purposes here, it is one way of learning just what features of our source images our identifiers are looking for (there are others of course). Remember that one of the points of our research is to understand the visual rhetoric of these images. If we can successfully trick the network, then we know what aspects of the network we should be paying attention to. Another intriguing aspect of this approach is that it allows a kind of ‘semantic arithmetic’ of the kind we’re familiar with from word vectors:
The easiest way to think about words and how they can be added and subtracted like vectors is with an example. The most famous is the following: king – man + woman = queen. In other words, adding the vectors associated with the words king and woman while subtracting man is equal to the vector associated with queen. This describes a gender relationship.
Another example is: paris – france + poland = warsaw. In this case, the vector difference between paris and france captures the concept of capital city.
I will admit that I haven’t figured out quite how to do this yet, but I’ve found various code snippets that should permit this.
Finally, as Wevers puts it, ‘The verisimilitude of the generated images is an indication of the meaningfulness of the learned subspace’. That is, if our generated images are not much good, then that’s an indication that there’s just far too much noise going on in our source data in the first place. Garbage in, garbage out. In Melvin’s poster, the GAN “was able to learn the variances in car models, styling, color, position and photographic composition seen in the adverts themselves.”
In which case, it seems that GANS are a worthwhile avenue to explore for our research.
Dominic Monn published an article and accompanying Jupyter Notebook on building a GAN trained on one of the standard databases, ‘CelebFaces Attributes data set’ which has more than 200,000 photographs of ‘celebrities’ (training dataset composition is a topic for another post). It’s probably a function of my computer but I couldn’t get this up and running correctly (setting up and using AWS computing power will be a post and tutorial in due course). It is interesting in that it does walk you through the code, which is not as forbidding as I’d initially assumed.
I had more success with Taehoon Kim’s ‘tensorflow implementation of “Deep Convolutional Generative Adversarial Networks”', which is available on Github at https://github.com/carpedm20/DCGAN-tensorflow. I don’t have a GPU on this particular machine, so everything was running via CPU; I had to leave my machine for a day or two, and also use the caffeinate command on my Mac to keep it from going to sleep while the process ran (quick info on this here).
I had a number of false starts. Chief amongst these was the composition of my training set.
- You need lots of images. Reading around, 10 000 seems to be a bottom minimum for meaningful results
- The images need to be thematically unified somehow. You can’t just dump everything you’ve got. I went through a recent scrape of instagram via the tag
skullforsaleand pulled out about 2300 skull images. That was enough to get the code to run, but as you’ll see, not the best results. Of course, I was only trying to learn how to use the code and work out what the hidden gotchas were.
Gotchas
Ah yes, the gotchas.
- images have to be small. Resize them to 256 x 256 or 64 x 64 pixels. Use Imagemagick’s ‘mogrify’ command.
- images have to be rgb
- weird errors about casting into array eg https://github.com/carpedm20/DCGAN-tensorflow/issues/162:
ValueError: could not broadcast input array from shape (128,128,3) into shape (128,128)means that we have to use Imagemagick’s ‘convert’ command there too. - greyscale images screw things up. Convert those to RGB as well
- running the code: use the dockerized version, and put the data inside the DATA folder.
- running the
main.pyscript:--cropalways has to be appended.
Command snippets:
convert image1.jpg -colorspace sRGB -type truecolor image1.jpg
make sure there are no grayscale images
identify -format "%i %[colorspace]\n" *.jpg | grep -v sRGB
convert images to 64x64
mogrify -resize 64x64 *.jpg
convert to sRGB
mogrify -colorspace sRGB *.jpg
run main.py
python main.py --dataset=skulls --data_dir data --train --crop`
Results?
I let the code run until it reached the end of its default iteration time (which is a function of the size of your images). Results were… unimpressive. With too small a dataset, the code would simply not run.
Some outputs:

After nearly an hour the first visualization of the results after a mere two epochs of iterations… a dreamy mist-scape as the machine creates.

In this mosaic, which represents the results from my first actual working run (20 epochs), you can, if you squint, see a nightmarish vision of monstrous skulls. Too few images, I thought (about a thousand, at this point). So I spent several hours collecting more images, and tried again…

Maybe I’m only seeing what I want to see, but I see hints of the orbital bones around the eyes, the bridge of the nose, in the top left side of each test image in the mosaic.
So. I think this approach could prove productive, but I need a) more computing power b) more images c) run for much much longer.
I wonder if I can remove my decision making process in the creation of the corpus from this process. Could I construct a pipeline that feeds the mass of images we’ve created into a CNN, use the penultimate layer and some clustering to create various folders of similar images, and then pass the folders to the GAN to figure out what it’s looking at, and visualize the individual neurons?
update 2019-02-24 I’ve had a lot more success using some higher end computing power I rented at Paperspace. Figuring out just how to use it though, well, that was a trial. This lesson from ml4a.github.io was invaluable.